얼마전 페이스북모임인 플랫폼전문가그룹의 저녁 토론회에 참석하였다. 주제는 <빅데이터 한국에도 필요한가> 토론회에는 기술, 사업, 전략 등 다양한 분야의 현업 전문가들이 함께 하였다.
모 기업의 데이터플랫폼 전문가의 강의 이후 토론회가 전개 되었다. 필자는 미디어 분야에서의 빅데이터 필요성과 향후 활용 가치를 고민하면서 다양한 분야의 시각을 이해하고자 참여하였다.
2012/01/15 – [TV 2.0 & 미디어2.0] – 방송의 미래 : TV3.0은 빅데이터 기반?
이용자의 정형, 비정형 데이터가 페타급 이상 증가하면서 빅데이터의 저장과 가공, 분석의 중요성이 대두되었다. 1952년 large scale 데이터라고 부를 수 있는 크기가 8백만 digit 수준이었으니 페타급 데이터는 가히 폭발적 크기이다.
빅데이터의 속성은 크게 볼륨, 속도(near time, real time), 다양성 등 인데 이러한 속성은 어떤 관점에서 출발하느냐에 따라 빅데이터의 활용성이 틀려진다고 한다. 가장 중요한 것은 3가지속성의 공통 분모인 고객의 가치(value) 기반에 접근 방식이 상위에 있다고 강사는 역설한다.
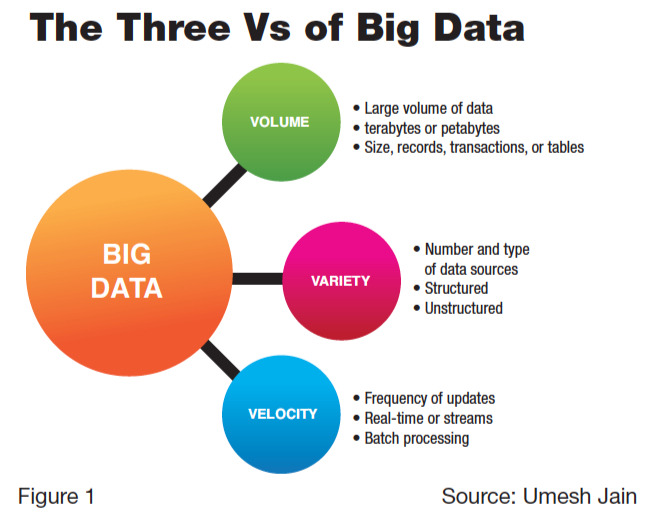
그런데 빅데이터의 기술적 이해를 설명한 뒤, 강사는 과연 한국에 페타급 데이터를 보유한 기업이 얼마나 되는지 묻는다. 현실적으로 페타급 데이터가 쌓이고 있는 서비스는 네이버 정도 (월 UV 2천5백만)인데 페타급 데이터를 가지고 있느냐와 이를 활용하고 있느냐는 다른 의미라는것.
TELCO들이 다루고 있는 고객의 빌링 데이터나 금융계의 데이터들도 크기는 크지만 이용자들의 이용 로그(usage log)를 개발 DB에 쌓는 수준이며 진정한 의미에서 빅 데이터의 활용은 부족하다고 분석한다.
빅데이터의 진정한 가치는 사용자 프로파일링에 기초하여 개인화, 검색, 상품 추천등으로 나타나야 한다고 설명한다.
이런 의미에서 국내에 과연 빅데이터는 있는가? 라는 물음에 빅데이터의 활용 관점에서 보자면 “없다”는 주장을 펼친다.
사실 빅데이터는 “빅”을 빼고 나면 CRM 과 같은 데이터마이닝에 기반한 마케팅 분석 툴과 비슷해 보인다. 이런 의미에서 보자면 빅데이터가 그리 특별하지 않다는 참석자들의 토론이 이어졌다. 많은 인터넷 기업들이 구글 애널리스틱을 활용하여 고객의 흐름을 분석하고 있고 대기업, 금융계는 전용 DW 솔루션을 활용하고 있는데 현실적으로 이정도 수준으로도 충분하다는 것이다.
대용량의 정보가 증가하면서 데이터의 기준이 테라를 넘어, 페타에서엑사, 제타급으로 늘어갈것은 자명한 사실이다. 웹과 모바일 사이트의 방문, 모바일앱 간의 이동과 검색 결과 값과 각종 미디어 서비스의 이용 통계, 커머스 정보 그리고 소셜네트워킹의 정보들이 축적되면서 데이터의 관리와분석은 핵심 경쟁력이 될것이다.
그러나 빅데이터는 데이터를 축적하는 행위와 분석하는 행위로 나누어 볼때 현실적 측면에서 다소 호들갑스러운 측면이 있다는 것이 토론 참석자들의 견해이다.
빅데이터의 활용 결과는 추천, 개인화로 비즈니스 단위가 만들어져야 한다. 아마존의 매출중 30%가 추천으로 인해 발생된다는 분석에서 보듯 구조화된 사업으로 이어져야 하지만 국내의 데이터활용 사례는 ‘빅데이터’에 걸맞지 않는다는 것이다.
빅데이터의 비즈니스 활용은 우선 데이터의 축적이 중요하다. 그 행위는 기업이나 서비스 마다 중요도가 다르고 방법론도 달라야 한다. 페이스북은 이용자 프로파일링에 중점을 두고 아마존은 상품 거래 행위 간의 추천 정보를 모으는데 주력한다. 구글의 구글플러스는 소셜네트워킹 서비스로의 독자적 행보 라기 보다는페이스북 연동을 통해 페이스북의 연계 정보를 흡수하려는 전술이라는 해석도 빅데이터 관점에서 보면 장기적 데이터 축적 행위라고 토론자들의 의견이 이어졌다. (구글 플러스에 대한의견은 다수의 동의를 받기 어려울수도 있지만)
데이터의 축적은 장기적 행위이며 축적과 동시에 활용으로 이어지기 보다는 고객의 경험 데이터가 축적될수록 활용 가치도 커지는 단계적 과정을 거친다. 애플의 음성 인식 인터페이스인 Siri가 대표적 사례이다.
빅데이터가 축적되어 고객에게 제안하는 구조화된 서비스들은 ‘넛지방식’으로 나타나야 한다. 필자의 신용카드 거래액은 3월에서10월까지 꾸준히 유지되다 11~12월에 감소한다. 매해1월 이면 어김없이 문자메시지와 전화를 통해 할인을 유도하는 신용카드 회사의 마케팅 제안을 받는다. 이러한 고전적인 CRM 방식에 익숙한 고객들은 ‘나의 구매 행위’를 활용하는 기업의 마케팅 활동을 긍정적 시각으로 수용하지 않는다.
기계적 방식의 데이터 분석은 개인의 정보를 근간으로 하기 때문에 개인이 알아채는 순간 오히려 역 효과를 낼 우려가 있다. 특히 경쟁 서비스들의 옵션이 도처에 깔려 있는 ‘선택의 무한 시대’ 에는 어설픈 빅데이터가 힘을 발휘하기 어렵다.
이런 의미에서 빅데이터와 다른 방향으로 ‘큐레이션’ 개념이 서있다.
최근 각광을 받고 있는 큐레이션은 기계적 검색 결과가 제안하는 개인화된 정보가 오히려 개인들에게 혼란을 야기할 수 있다는 IT의 역설적 상황에 토대를 두고 있다.
정보를 필터링 해주는 것은 기술의 힘이 아니라 인간의 힘이며 인간에 의해 콘텐츠를 수집하고 편집해서 보여주는 것이 가장 좋은 필터링과 검색이라는 것이 곧 ‘큐레이션’ 이다. 빅데이터가 Real time을 강조하고 있다면 큐레이션은 Right time을 강조한다.
빅데이터가 기술 지향적 관점과 비즈니스 관점의 간극이 매우 큰 반면 큐레이션은 이미 여러 IT 장르에서 활용되고 있어 다소 실용적이다. 이런 점에서 빅데이터는 아직 개념적이라는 평가를 벗어나기 어렵다.
토론의 참석자들은 빅데이터의 중요성을 인정하면서도 실제로 국내에는 제대로 활용되지 못하고 있음을 지적한다.
빅데이터 담론은 기술에서 마케팅 영역까지 매우 광범위한 주제이다. 빅데이터가 과거 CRM 열풍처럼 몇몇 솔루션 회사나 SI 회사들의 돈벌이 대상이 되어서는 안된다.
CRM은 해당 산업 분야에 독립적으로 존재하는 고객들의 정보를 대상으로 한다. 반면 빅데이터의 이용자 경험 정보들은이종 분야를 교차하고 있다. 특히소셜네트워킹의 비정형 데이터를 빼놓을 수 없다.
빅데이터는 CRM 과 같이 완성된 형태의 “올인 솔루션”이 아니다. 기술 측면의 빅데이터 보다 사업적 측면의 빅데이터 가치에 대해 더 깊은 고민이 필요하다.
글 : 제레미
출처 : http://jeremy68.tistory.com/316