
이세돌과 구글의 바둑로봇 ‘알파고(AlphaGo)’와의 대결에 앞서 지난 4일, 앱센터와 소프트웨어정책연구소, 조선비즈가 공동 주최한 ‘기계학습과 알파고‘ 세미나가 조선비즈 교육장에서 개최되었다.
차세대 핵심기술로 주목받는 기계학습의 원리와 한계점을 다룬 이번 세미나는, 김진형 교수의 강연을 시작으로 김석원 박사의 알파고 알고리즘 강연까지 이어졌다.
먼저 김진형 교수는 “컴퓨터 70년 역사가 인공지능의 역사이자 소프트웨어의 역사”라고 운을 떼었다. 그는 “인공지능 개발 방법론에는 크게 3가지가 있는데, 사람의 지식을 기계로 옮긴 ‘지식 처리형’과 신호 데이터로부터 공통 성질을 추출한 ‘데이터 기반형’, 그리고 이 2가지를 합친 통합형이 있다.”고 소개하였다. 그러면서 “‘가상 비서’와 ‘그림 내용 설명하는 로봇’이 대표적인 통합형 사례”라고 언급하였다.
그는 특정 문제의 정답을 예측해내는 기계학습(머신러닝; Machine Learning)에 대해 “어떤 식으로든 특성을 추출해서 분류하는 시스템을 만들어야 하는데, 이 과정을 ‘학습’이라고 한다.”고 말하면서 “특성의 선택이 기계학습을 통해 패턴을 인식하고 오류 값을 줄여나가는 성능을 좌우한다.”고 설명하였다.
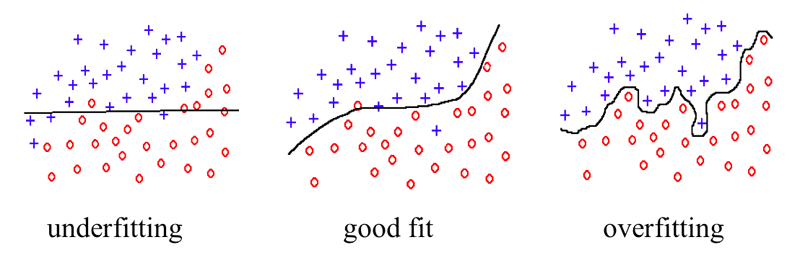
특히 “특성을 많이 추출하여 차원이 높아질수록 데이터 요구량이 급격히 많아지는 ‘차원의 저주’가 생기므로 유효한 통계를 내기 어려워진다.”고 설명하면서 “인식 방법론을 설계한 후 데이터 훈련 시 부적합(Underfitting)은 당연히 피해야 하지만, 과적합(Overfitting)에 치우친 건 아닌지 확인하면서 최상의 일반화 능력을 보유한 시스템(Good Fit)을 만드는 게 기계학습의 가장 큰 목적”이라고 강조하였다.
이후 그는 이러한 패턴 인식에 있어 신경망 원리를 도입한 의사결정 시스템을 소개하였다. 그는 우선 단층 구조에서부터 복층 구조까지 설명한 후 “1960년대에 단층 구조 신경망으로는 현실에서 일어나는 문제를 풀 수 없다는 결론을 얻었고, 마침내 2005년 다층 신경망에 잘 작동하는 학습 방법론의 총칭인 ‘딥러닝(Deep Learning)’이 등장했다.”고 밝혔다.
딥러닝에 관해 김 교수는 “층마다 자율학습기법의 선행학습을 별도로 시킨 후 층층이 쌓아 통합 훈련을 통해 미세 조정하는 방식”이라고 설명하면서 “데이터 훈련이 초기 무작위 상태에서 출발하지 않으므로 로컬 극점에 빠지지 않을뿐더러 적은 데이터로도 과적합되지 않고, 은닉층(Hidden Layer)이 원하는 특성을 갖도록 학습시킬 수 있다.”고 밝혔다.
그는 “이러한 강점을 바탕으로 현재 딥러닝 분야에서는 페이스북의 ‘딥페이스(DeepFace)’, 구글의 ‘페이스넷(Face Net)’처럼 100%에 가까운 얼굴인식률을 자랑하는 얼굴인식 알고리즘, 2010년 이후 음성인식 오류를 5% 이하로 떨어뜨린 음성인식 알고리즘 등 성공사례가 나타나고 있다.”고 언급하기도 하였다.
그러나 그는 “이러한 기술이 기계학습의 종점이 아니”라며 한계점을 지적하였다. “순수하게 딥러닝 기술로만 만들어진 프로그램이 언제쯤 세상에 나올지 알 수 없으며, 현재 우리가 만든 시스템은 모두 단일 기능만 수행한다.”면서 범용성이 있는 인공지능의 부재를 환기한 그는 “쉽게 말해 알파고는 바둑만 둘 줄 알지만, 이세돌은 퀴즈도 푼다.”고 비유하였다.
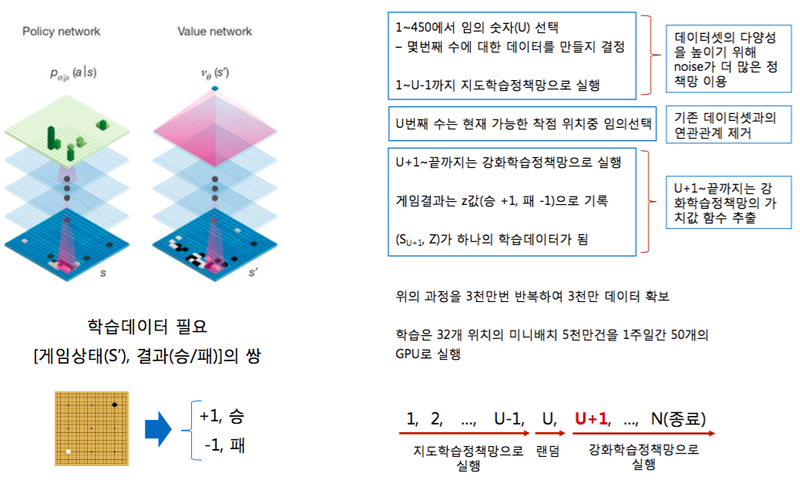
한편, 김석원 박사는 이어서 “알파고의 핵심은 최적의 수를 찾는 정책망(Policy Network)과 승자를 예측하는 가치망(Value Network), 이 2가지의 신경망을 결합한 ‘몬테카를로 트리탐색(MCTS; Monte Carlo Tree Search)’ 알고리즘”이라고 설명하였다.
그는 “지도학습정책망으로 실행한 후 한 수를 무작위로 둔다. 그 뒤부터는 강화학습정책망으로 다음 수를 어느 위치에 놓을 것인지 정한다.”며 바둑돌 놓는 과정을 소개하였다. 그러면서 “만약 강화학습법만으로 수를 둔다면 자기가 이기던 방식을 계속 강화하여 예외적인 상황에 대비하기 어려워진다.”면서 바둑 경기 초깃값을 지도학습정책망으로 실행하는 이유를 밝혔다.
또한, 그는 “알파고는 상대 선수가 생각할 때에도 30초당 약 10~20만 번의 시뮬레이션을 수행할 것으로 추정된다.”고 밝혔다.
끝으로 그는 “알파고의 알고리즘은 복잡한 요소를 고려한 의사결정으로 문제를 푸는 방법으로써 단순히 바둑용으로 만든 게 아니므로 승부가 중요한 건 아니”라고 강조하면서 “의료진단, 금융 등 다양한 분야에서 활용될 것”이라고 전망하였다.
You must be logged in to post a comment.