
[스피링크 ‘TEXTNET’ 서비스의 탄생]
스피링크(대표 고경민)는 2020년 4월 운영하던 심리 상담 서비스를 종료하고, 텍스트 전문 서비스인 TEXTNET으로 사업을 전환하였다. 그리고 출시 1년 만에 7억이라는 매출을 달성했다. 2021년을 마무리하고 있는 현재 전년도 매출을 넘어서 활발히 투자 유치 중이다.
전혀 상관없어 보이는 심리상담서비스에서 텍스트 사업으로 전환하게 된 계기는 과연 무엇일까?
“심리상담서비스를 운영하면서 ‘대화의 중요성’을 알게 됐습니다. 서비스를 운영하기 전에는 상담사의 관련 지식과 경력이 서비스 만족도에 있어서 가장 중요할 거라고 생각했습니다. 하지만 만족도 평가에서 계속 높은 점수를 받던 상담사 분은 경력이나 지식이 다른 분들에 비해 떨어지던 분이었죠. 심리 상담 서비스를 이용하는 분들은 ‘공감을 바탕으로 한 사람다운 대화’를 원하고 있던 거였습니다. 즉, 심리와 텍스트 데이터 구축이라는 형식상 전혀 다르게 보이는 아이템처럼 느껴지지만, 자세히 들여다보면 잘 구현된 인간의 대화를 분석하여 AI가 학습할 수 있도록 한다는 점에서 같은 사업 방향을 갖고 있다고 생각합니다. 기존에 운영하던 서비스의 결을 일정 수준 유지 및 활용하며 새롭게 서비스를 운영하게 되었습니다.”
 [대기업이 먼저 알아본 TEXTNET 서비스]
[대기업이 먼저 알아본 TEXTNET 서비스]
TEXTNET 서비스를 이용하는 고객사의 70% 이상은 대기업 AI팀이다. 이미 이미지, 음성 레이블링 영역은 확장될 만큼 확장된 AI 시장에서 ‘텍스트 전문’으로 TEXTNET의 영역을 넓혀갈 수 있었던 이유는 무엇일까.
그 이유는 TEXTNET의 독특한 포지션에서 비롯된 경쟁력을 통해 알 수 있다.
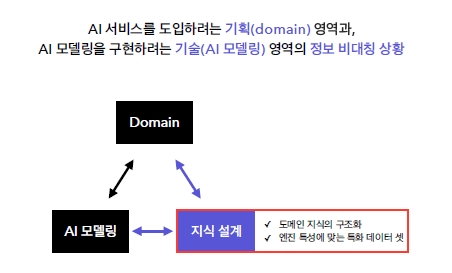 “AI 서비스 시장에는 기획(domain)과 기술(AI 모델링) 사이에 정보비대칭 현상이 존재합니다. 이를 해결하기 위해 ‘설계자’의 포지션을 선점하였고, ‘고도화’된 ‘맞춤형’ 데이터를 기획 및 구축하고 있습니다. 설계자란 ‘지식 설계’를 통해 AI 서비스의 ‘뇌’를 구성하는 역할입니다. 기술이 아닌 학습 데이터의 품질은 업체별 차별화를 위한 핵심 요소로 작용할 수밖에 없는 상황이며, 고품질의 데이터는 TEXTNET이 제공하고 있습니다. 고난도 설계 역량을 요구하는 ‘고객 맞춤형 고도화’ 서비스 제공을 통해 TEXTNET만의 경쟁력을 키워가고 있습니다.”
“AI 서비스 시장에는 기획(domain)과 기술(AI 모델링) 사이에 정보비대칭 현상이 존재합니다. 이를 해결하기 위해 ‘설계자’의 포지션을 선점하였고, ‘고도화’된 ‘맞춤형’ 데이터를 기획 및 구축하고 있습니다. 설계자란 ‘지식 설계’를 통해 AI 서비스의 ‘뇌’를 구성하는 역할입니다. 기술이 아닌 학습 데이터의 품질은 업체별 차별화를 위한 핵심 요소로 작용할 수밖에 없는 상황이며, 고품질의 데이터는 TEXTNET이 제공하고 있습니다. 고난도 설계 역량을 요구하는 ‘고객 맞춤형 고도화’ 서비스 제공을 통해 TEXTNET만의 경쟁력을 키워가고 있습니다.”
TEXTNET의 경쟁력인 고난도 설계 역량을 요구하는 ‘고객 맞춤형 고도화’ 서비스는 무엇일까.
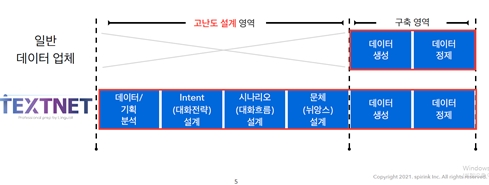 “기획 및 기술의 목표 달성을 위해 데이터의 수량에 집중하는 것이 아닌, ‘고품질의’, ‘전문적인’, ‘오류가 적은’ 똑똑한 데이터 (Small&Smart Data)를 ‘기획’에 집중하는 것입니다. TEXTNET 서비스의 카테고리는 크게 ▲데이터 구축 (페르소나/일반 대화 등 멀티턴 대화 데이터) ▲데이터 레이블링 (대화/문서 요약, 혐오/유해 평가 등) 두 가지로 나눌 수 있습니다. 데이터 기획 및 설계부터 구축, 더 나아가 검수까지 데이터의 모든 영역을 담당할 수 있다는 게 TEXTNET 서비스의 강점입니다”
“기획 및 기술의 목표 달성을 위해 데이터의 수량에 집중하는 것이 아닌, ‘고품질의’, ‘전문적인’, ‘오류가 적은’ 똑똑한 데이터 (Small&Smart Data)를 ‘기획’에 집중하는 것입니다. TEXTNET 서비스의 카테고리는 크게 ▲데이터 구축 (페르소나/일반 대화 등 멀티턴 대화 데이터) ▲데이터 레이블링 (대화/문서 요약, 혐오/유해 평가 등) 두 가지로 나눌 수 있습니다. 데이터 기획 및 설계부터 구축, 더 나아가 검수까지 데이터의 모든 영역을 담당할 수 있다는 게 TEXTNET 서비스의 강점입니다”
“또한 위와 같이 전문적인 서비스가 가능한 이유는 다음과 같습니다.
▲국어국문학·심리학·데이터 과학 등 석박사 비율 60% 이상으로 구성된 전문가 집단, 체계적인 작업자 선발·관리 시스템을 통해 숙련된 데이터 레이블러 구축 ▲난도별·영역별 레퍼런스 보유 입니다.
이렇게 독점적인 포지션 선점과 강점이 명확한 서비스 제공을 통해 지속적인 상승세를 이룬 것 같습니다.”
[TEXTNET 성장 전략]
빠르게 변화하는 AI 시장의 흐름에 TEXTNET은 어떻게 대응하여 상승세를 이어갈까.
“메타버스 플랫폼 내의 캐릭터와 디지털 휴먼에 맞춘 서비스를 제공하고자 합니다. 현재 해당 시장의 확산세는 대단합니다. 하지만 아직 ‘사람다운’, ‘무한 확장이 가능한’ 상태로 구현하기는 어렵습니다.”
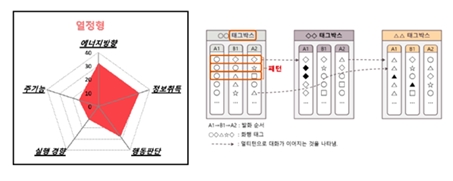
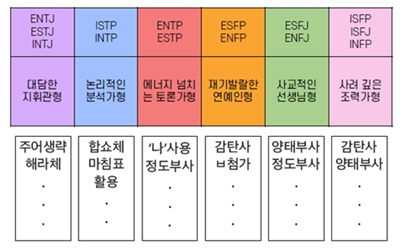
“‘분석 심리학’과 ‘형식 언어학’ 2가지 프레임워크를 기반으로 ‘페르소나 데이터’를 구축합니다. 캐릭터가 실제 사용하는 표현 양식, 행동 양식, 말투 등을 녹여낸 ‘문장’ 데이터를 구축합니다. 통상적으로 설계(기획)/구축/검수 3가지 단계를 거쳐 데이터를 구축하고 있습니다. 페르소나 데이터 구축에서 그치는 것이 아니라, 더 고품질의 데이터 구축을 위해 혐오 발언 레이블링, 토픽 기반 멀티턴 대화 데이터 구축 등 활발한 논의를 진행 중입니다.”
You must be logged in to post a comment.