알지비에이가 데이터 저장 및 검색 기술의 새로운 지평을 열었다. 다년간의 연구와 혁신 끝에 알지비에이는 차세대 AI 벡터 데이터베이스 ‘KalishDB’의 개발을 선언했다. 이번 발표는 데이터 관리 및 검색 분야에서 혁신적인 변화를 가져올 전망이다.
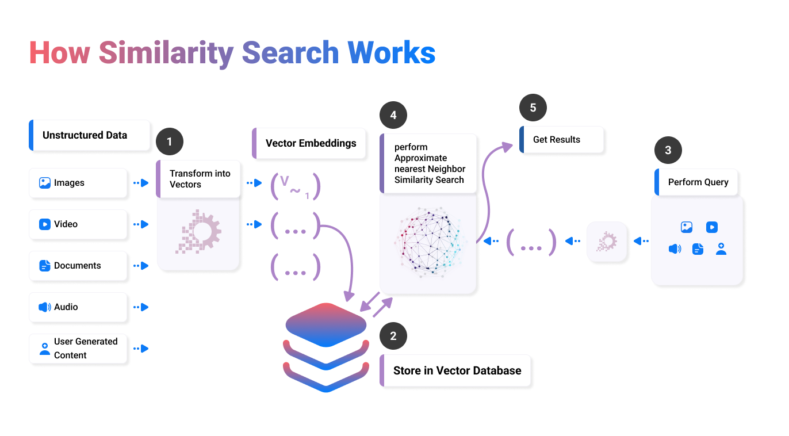
KalishDB의 가장 큰 특징은 문맥적 의미를 파악하여 유사한 문맥을 가진 데이터를 빠르게 검색해내는 능력이다. 동시에 다양한 인덱스 알고리즘의 지원을 통해 대규모 데이터 처리 속도를 상당히 향상시켰다. 이러한 기능은 기존 벡터 데이터베이스가 주로 사용해 온 HNSW (그래프 기반 인덱스) 외에도 IVF (양자화 기반 인덱스) 및 SCANN (양자화 기초(기반) 인덱스)을 모두 포함한다. 이것은 데이터 저장 및 검색 효율의 극대화를 의미한다.
다국어 지원 역시 중요한 혁신 중 하나로 자리 잡았다. 대부분의 오픈소스 벡터 데이터베이스가 제한된 언어에 대해서만 저차원 임베딩을 지원하는 반면 KalishDB는 내장된 고차원 임베딩 기술을 통해 더 많은 언어에 대한 지원을 가능하게 했다. 이는 고차원의 임베딩을 통해 데이터 처리의 정확도와 일관성을 한층 더 높인다는 점에서 큰 의미를 지닌다. 뿐만 아니라, 이 기술은 multi-lang으로 구현되어 있어 여러 언어 간의 상호 작용도 원활하게 가능하다. 이를 통해 사용자들은 별도의 외부 임베딩 기술에 의존하지 않고도 다양한 언어로 된 고차원의 정확도 높은 데이터 가공이 가능하게 된다.
또한 KalishDB는 RAFT 기반 노드 합의 알고리즘을 활용한 고가용성 클러스터 시스템을 내장하여 대규모 환경에서도 안정적이고 빠른 서비스를 제공한다. 이러한 고급 기능을 갖춘 KalishDB는 현재 알지비에이가 서비스 중인 리뷰 앱 ‘Rely’의 스마트 검색 엔진으로 이미 활용되며 그 성능을 입증하였다. 클라우드 시스템을 통해 개인 및 기업 사용자를 위한 SaaS 서비스로의 활용도 구상 중이다.
향후 KalishDB는 검색 증강 생성(Retrieval-Augmented Generation)을 넘어서, 사용자의 이전 대화를 기반으로 추론하여 검색 계획을 재수립하는 Semantic-Reasoning 기술을 도입할 계획이다. 이는 LLM의 장기 메모리 역할을 향한 알지비에이의 궁극적인 방향성을 보여준다. 또한, KalishDB의 코어를 중심으로 개인화된 LLM을 목표로 하는 온디바이스 AI 시장에서의 적용 가능성도 모색하고 있다. 이는 소규모 LLM과의 통합을 통해 강화될 전망이다.
이 같은 다양한 혁신을 통해 알지비에이는 데이터 관리 및 검색 기술의 새로운 장을 열고 있다. KalishDB의 발표는 단순히 새로운 기술의 등장을 넘어, 데이터 처리 방식에 있어 진보적 변화를 이끌어내고 있는 것으로 평가된다.
- 관련 기사 더 보기
You must be logged in to post a comment.