人工知能データとソリューションの専門企業であるPlitoは、AIモデルの多言語認識率向上のために高品質アラビア語音声データを収集する新規プロジェクトを開始したと10日、明らかにした。
今回のプロジェクトは、音声認識(STT)モデルで比較的低い認識率を示すアラビア語の性能改善を目標に企画された。アラビア語は標準語であるMSA以外にも30以上の方言が存在し、日常会話では標準語と方言を混用するコード切り替え現象が頻繁にAI学習データ構築難易度の高い言語で評価される。
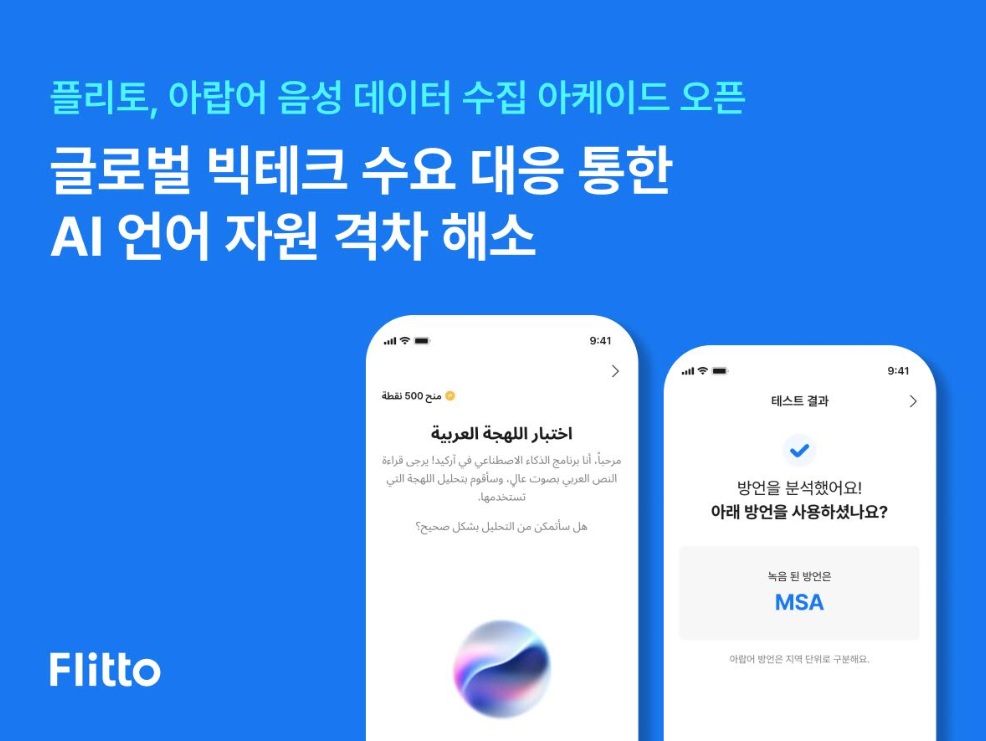
プリトは自社モバイルアプリケーションに搭載された音声データ収集機能「アーケード」を活用してアラビア語の音声データ収集イベントを運営している。参加者は、提示された文章を読み、音声を録音すると、AIシステムが発話データを分析して方言タイプを判別する方式だ。方言の区別が不確実な場合は、追加の文章を提示し、再参加を誘導することでデータの精度を高める。
同社は、グローバルビッグテク企業を中心に多言語音声データの需要が継続的に増加するにつれて、実際のプロジェクト要求だけでなく、潜在需要に先制的に対応するために今回のプロジェクトを推進したと説明した。
プリトは今回のデータ収集を通じて発話者のイントネーション、発音パターン、語彙選択など言語的多様性が反映された学習用データ構築が可能と見ている。これをもとに、言語資源偏差によるAI学習偏向を緩和し、実際の使用環境でも高い認識率を実現できるデータセットに高度化する計画だ。
イ・ジョンス・プリト代表は「アラビア語は全世界4億人以上が使用する主要言語だが、AI学習用データは相対的に不足した低資源言語」とし「今回のプロジェクトを通じて、アラビア語の実際の使用状況を忠実に反映したデータ構築で、グローバルAIモデルのアラビア語認識品質の向上に寄与する」と述べた。
- 関連記事をもっと見る
You must be logged in to post a comment.