우리 삶에서 인공지능이 관여하고 적용되는 부분은 과연 어디까지일까? 우리에게 인공지능은 최신 기술로 비춰지지고 있지만 이미 지난 1950년대부터 연구해오던 분야로 당시 컴퓨팅 파워로는 방대한 데이터를 처리하기 위한 하드웨어 능력이 턱없이 부족해 90년대까지도 제대로 빛을 못본 비운의 프로젝트였다. 구글 역시 지난 2011년까지는 몇몇 엔지니어의 주도해오던 프로젝트였다 2012년에 접어들면서 본격적으로 머신러닝 프로젝트가 시작됐다.
당시 나온 이론은 기계를 똑똑하게 만드는 것 보다 스스로 학습이 가능하도록 인간이 도와주는 게 훨씬 효과적이라는 판단에서다. 이를 수학적으로 접근해 입출력(I/O)만을 제시하고 나머지 해결 과정은 기계 스스로 찾을 수 있도록 만든 게 바로 머신러닝이다. 홍준성 구글코리아 엔지니어링 총괄 디렉터는 “일일이 사람이 모든 과정에 개입해야 하는 프로그래밍과는 개념 자체가 다르다”고 말한다.

우리가 가장 많이 알고 있는 머신러닝는 사례는 개와 고양이다. 사진을 보고 웅크리고 있는 동물이 개인지 고양이인지 분간해 내기까지 수십만장의 사진을 이용한 반복학습이 필요했다. 이렇게 축적한 데이터는 사람의 인지 능력이나 추론 능력을 본따 만든 수학적 이론(인공신경망, DNN)을 신호로 바뀌는데 이를 최적화하는 단계가 바로 머신러닝이다.
알아서 스스로 행동하는 로봇이 등장하고 자율주행 자동차처럼 눈에 보이는 것 말고도 인공지능은 이미 우리 삶 깊숙이 침투해 있다. 사자 사진을 보고 ‘lion’이라는 단어를 출력하고 음성을 듣고 텍스트로 변환하는 TTS, 외국어의 실시간 번역, 심지어 최근 이미지 분석 기술은 특정 사진을 보고 어떤 상황인지까지 묘사가 가능한 수준에 이르렀다. 이 모든것이 머신러닝을 적용하면서 생긴 변화다.
구글은 그들의 인공지능 기술을 활용해 보다 현실적인 부분으로 접근했다. 개인적으로 가장 공익적인 부분이라 생각하는 실시간 번역이다. 구글은 인공지능 기술을 자사의 서비스에 본격적으로 도입하면서 기존 문구 기반의 번역을 머신러닝 기반으로 바꾸기 시작했다. 현재 97개 언어간 번역이 가능한 상태. 증강현실을 이용한 ‘워드렌즈’는 불필요한 입력 과정없이 카메라로 번역이 필요한 언어를 비추는 것 만으로 번역이 가능하다. 처리하는 전과정에 머신러닝이 적용된 대표적인 사례다.

G메일, 인박스에 적용된 스마트 답장 기능 역시 편지 본문 내용을 인식하고 필요한 답장을 인공지능이 스스로 알아서 제안하는 기능이다. 현재 모바일 답장의 12% 가량이 이를 통해 이뤄지고 있다. 유튜브의 자동 캡션 역시 인공지능 기술이 접목된 서비스다. 화자의 음성을 인식해 자동으로 자막을 붙이고 이를 다시 10개 언어로 번역해준다. 현재 약 10억개의 영상에 적용돼 서비스 중이다.
인공지능은 때론 소프트웨어, 하드웨어와 함께 적용되는 경우도 있다. 픽셀폰에 적용된 사례가 대표적이다. 인물 촬영 기능이라 부르는 피사체 이외의 배경이 흐릿하게 블러 처리되는 영상 처리는 보통 듀얼 카메라를 통해 심도 정보를 알아내고 하드웨어적으로 처리한다. 카메라 한개로 처리하기 위해서는 머신러닝이 필수적이다. 또렷하게 보여야 하는 피사체와 흐릿하게 만들어야 하는 부분의 경계를 나누는 게 바로 인공지능의 몫이다.

인공지능 비서인 구글 어시스턴트는 언어 분야의 머신러닝이 집적된 결과물이다. 기존 문장에 대한 이해와 인식은 기본이고 사용자가 누구인지, 취향, 상황 같은 부가적인 정보를 복합적으로 처리해야만 대화 형태의 자연어 처리가 가능해서다. 무엇보다 대화에 대한 이해가 중요하다. 한마디로 기계가 사람의 말귀를 알아먹어야 말이 통한다.
기본적인 서비스에 인공지능 기술을 도입후 다음 단계는 인프라 확장이었다. 텐서플로우는 머신러닝을 전공하거나 공부하는 이들에게 가장 익숙한 머신러닝 학습도구다. 구글에서 AI를 집중해 연구하는 구글 브레인에서 그동안 써온 2세대 머신러닝 툴로 지난 2015년 11월 오픈소스로 공개했다. 현재 머신러닝 툴 분야에서 가장 많은 사용자를 확보하고 있다.

클라우드 서비스를 통해 머신러닝 API를 공개해 누구나 쓸 수 있는 사전학습 모델을 만들어 자체 서버를 두고 개발하기 벅찬 스타트업도 쓸 수 있도록 문턱을 낮췄다. 클라우드 TPU는 연장선 상에 위치한 하드웨어다. 여전히 머신러닝을 다루는 PC는 고성능의 GPU 처리를 요구하기 때문이다. 구글 하드웨어팀은 머신러닝을 위한 별도의 하드웨어를 개발해 데이터 센터에 적용 중이다.
유방암 진단을 하려면 10기가 픽셀 수준의 고해상도 이미지 수십장이 필요한데 아직도 의사가 직접 분석을 해야하는 상황이다. 이런 분야에 머신러닝을 적용해 특정 영역을 좁혀 오진 확률을 낮추는 데 인공지능이 쓰인다. 당뇨성 망막병증 같은 안과질환 검사에도 이미 적용 중이다.
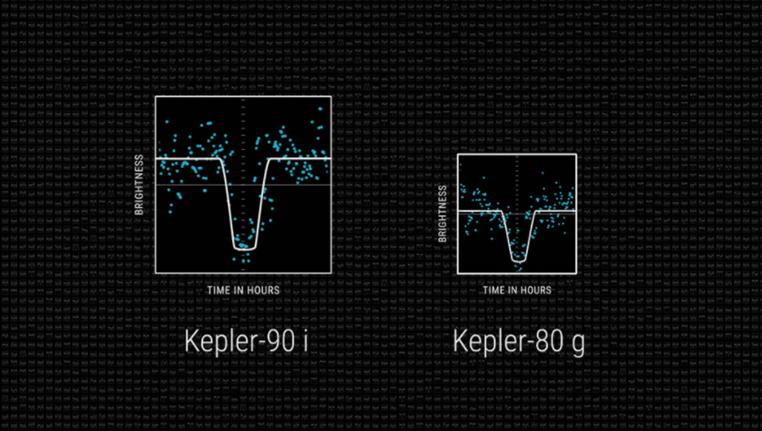
구글 브레인팀의 시니어 리서치 소프트웨어 엔지니어 크리스 샬루(Chris Shallue)는 업무의 20%를 개인 관심사 연구에 활용하는 제도(20%프로젝트)를 통해 머신러닝을 천체 관측에 활용했다. 나사가 개발한 케플러 우주 망원경이 4년간 30분마다 한번씩 우리 은하계에 20만개에 별을 관측한 자료를 통해 약 140억개의 데이터 포인트를 얻었는데 머신러닝 기술을 적용해 항성 데이터 670개를 추출해 냈다. 그 결과 케플러-90i와 케플러-80g 행성을 찾아냈는데 케플러 90i는 항성 케플러 90을 공전하는 8번째 행성. 우리 태양계 외부에 존재하는 태양계 중 최초로 8개의 행성을 보유한 항성이기도 하다. 지구보다 30%나 큰 면적을 지녔지만 섭씨 426도 되는 표면 온도 때문에 생물이 살기엔 부적합한 환경이라고.
또 한가지는 에너지 분야다. 클라우드 서비스를 제공하는 기업은 축구장 몇 배 규모의 데이터 센터를 보유하고 있다. 안에 있는 서버는 모두 쉴틈없이 열을 내뿜다 보니 냉각에 대한 부분에 특히 민감한 편이다. 예전에는 이런 공조시스템 관리를 숙련된 기술자가 직접 조절했지만 이 분야에 머신러닝을 적용해 냉각은 40% 절감, 전체 에너지 효율성은 15% 개선효과를 얻었다. 실제 구글 데이터 센터에 적용 중이다.
머신러닝 기술이 더이상 특정 소수 집단의 기술이 아닌 보편 타당한 기술이라는 목표 아래 훈련 프로그램을 운영중이다. 작년에만 18000명의 구글 엔지니어가 수료했고, 일부 대학에서 파일럿으로 교육 프로그램을 통해 교육 중이다. 한국어 버전도 조만간 공개해 국내 대학에서도 구글의 머신러닝 교육 프로그램 혜택을 받을 수 있게됐다.
하지만 아직까지 머신러닝의 궁극적인 목표인 신경망 최적화는 극소수의 엔지니어만이 설계 가능한 고급 기술이다. 인공지능이 만드는 인공지능인 AutoML은 이런 물음으로 시작된 프로젝트다. 머신러닝 전문가가 아니더라도 자동으로 진화할 수 있는 솔루션으로 클라우드를 통해 꾸준히 머신러닝 시스템을 개선하고 진화시킨다. 공부하라고 책 사주고 책상에 앉히더니 급기야 가정교사까지 붙여 준 격이다.
이게 무슨 ‘홍익인간’ 개념이냐 반문할 수 있겠다. 분명한건 ‘세상에 밑지고 파는 장사’는 없다는 사실이다. ‘Don’t be evil’이 구글의 사훈(?)이라지만 시장 독점 상황이 아니라면 기술 공개를 통한 빠른 보급이 그 시장에서 ‘게임체인저’가 되는 지름길임에 분명하다. 90년대 초 유닉스 기반 서버가 판치던 시절 리눅스를 세상에 공짜로 뿌린 리눅스 토발즈가 좋은 예다.
You must be logged in to post a comment.