AI 테크 기업 크라우드웍스가 자사 AI 데이터 전처리 솔루션 ‘알피 널리지 컴파일러(Alpy Knowledge Compiler)’에 적용된 핵심 기술인 ‘문서 복잡도 분석 기반 문서 자동화 처리 기술’에 대한 특허를 출원했다고 22일 밝혔다.
해당 기술은 RAG(Retrieval-Augmented Generation) 기반 AI 에이전트 개발에 필수적인 비정형 데이터 전처리 과정에서 문서의 구조적 복잡성을 정량적으로 분석해 자동화 적용 여부를 판단하는 방식이다. 전처리 품질 저하 및 자원 낭비를 방지하고, 문서 유형에 따라 전문가 투입 여부를 사전에 결정함으로써 작업 효율성과 비용 최적화를 도모할 수 있다.
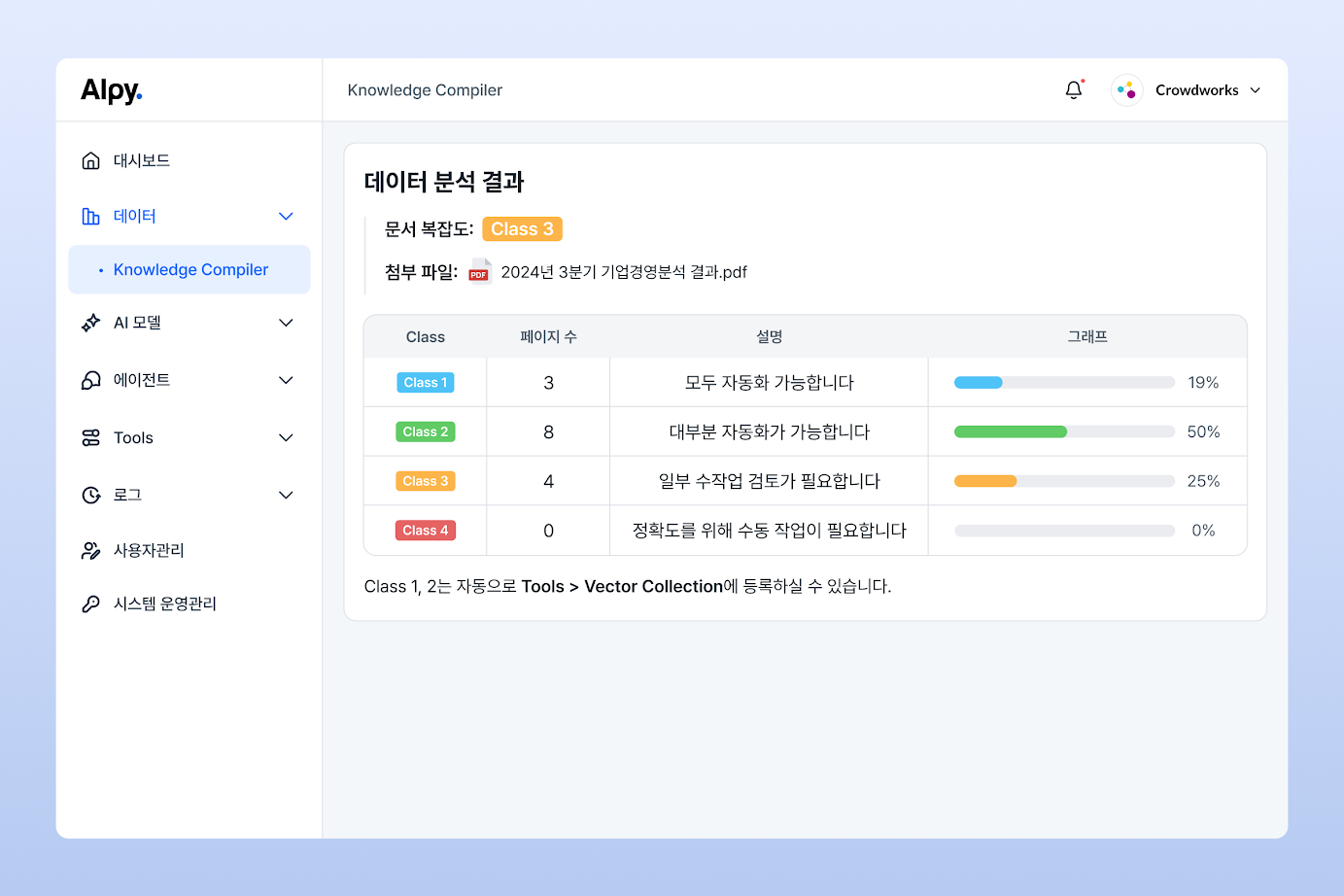
크라우드웍스에 따르면, 이 기술은 문서의 복잡도에 따라 Class 1부터 Class 4까지 네 단계로 분류하고, 단순 구조의 문서는 자동화 전처리 방식으로, 복잡한 구조의 문서는 전문가 파싱을 병행하는 기준을 제시한다. 이를 통해 데이터 전처리 오류 발생 가능성을 예측하고, 인력 및 일정 관리에도 활용 가능하다는 설명이다.
해당 기술은 현재 크라우드웍스의 자체 개발 솔루션인 ‘알피 널리지 컴파일러’에 적용되어 운영 중이다. 이 솔루션은 OCR(광학문자판독), 파싱, 청킹 기능을 기반으로 다양한 형식의 문서를 AI가 학습 가능한 형태로 변환하며, 한글(HWP/HWPX), PDF, 워드, 엑셀 등 다수의 문서 포맷을 지원한다. 테이블 내 중첩 구조나 차트, 이미지 등 시각적 요소까지 인식해 메타데이터를 생성하며, LLM(초대형 언어모델) 및 VLM(비전언어모델)을 활용한 고도화된 처리 기능도 제공할 예정이다.
최근 비정형 데이터의 자산화에 대한 기업 수요가 증가함에 따라, 크라우드웍스는 해당 솔루션을 통해 국내외 다양한 산업군의 전처리 수요에 적극 대응하고 AI 기반 업무 자동화 분야에서의 경쟁력을 강화해 나갈 방침이다.
김우승 크라우드웍스 대표는 “이번 특허 출원은 문서 복잡도 분석 기반 기술을 통해 데이터 전처리의 정밀성과 효율성을 높인 첫 사례로, AI 데이터 전처리 전문기업으로서의 차별화를 입증하는 계기”라며 “알피 널리지 컴파일러는 현재 다양한 기업의 문의가 이어지고 있으며, 기업용 AI 시장에서의 적용 확대가 기대된다”고 밝혔다.
- 관련 기사 더보기
Crowdworks, 'Document Complexity Analysis' Technology Patent Application
AI tech company Crowdworks announced on the 22nd that it has applied for a patent for 'Document Complexity Analysis-Based Document Automation Processing Technology', a core technology applied to its AI data preprocessing solution 'Alpy Knowledge Compiler'.
This technology quantitatively analyzes the structural complexity of documents and determines whether automation should be applied in the unstructured data preprocessing process essential for developing AI agents based on RAG (Retrieval-Augmented Generation). It can prevent preprocessing quality degradation and resource waste, and promote work efficiency and cost optimization by deciding in advance whether to involve experts depending on the document type.
According to Crowdworks, this technology classifies documents into four levels from Class 1 to Class 4 based on their complexity, and suggests a standard for automatically preprocessing documents with simple structures and expert parsing for documents with complex structures. Through this, it is explained that it can be used to predict the possibility of data preprocessing errors and also for human resources and schedule management.
The technology is currently being applied and operated in Crowdworks' self-developed solution, 'RP Knowledge Compiler'. This solution converts various types of documents into a form that AI can learn based on OCR (optical character recognition), parsing, and chunking functions, and supports multiple document formats such as Hangul (HWP/HWPX), PDF, Word, and Excel. It recognizes visual elements such as nested structures in tables, charts, and images to generate metadata, and plans to provide advanced processing functions using LLM (large-scale language model) and VLM (vision language model).
As corporate demand for asset management of unstructured data has increased recently, Crowdworks plans to actively respond to the preprocessing needs of various industries at home and abroad through its solutions and strengthen its competitiveness in the field of AI-based work automation.
Kim Woo-seung, CEO of Crowdworks, said, “This patent application is the first case of increasing the precision and efficiency of data preprocessing through document complexity analysis-based technology, and it is an opportunity to prove our differentiation as a specialized AI data preprocessing company.” He added, “We are currently receiving inquiries from various companies about the RPI Knowledge Compiler, and we expect its expanded application in the enterprise AI market.”
- See more related articles
クラウドワークス、「文書複雑度分析」技術特許出願
AIテック企業クラウドワークスが自社のAIデータ前処理ソリューション「Alpy Knowledge Compiler」に適用されたコア技術である「文書複雑度分析ベースの文書自動化処理技術」に対する特許を出願したと22日明らかにした。
当該技術は、RAG(Retrieval-Augmented Generation)ベースのAIエージェント開発に不可欠な非定型データ前処理過程で文書の構造的複雑性を定量的に分析して自動化適用可否を判断する方式である。前処理の品質の低下と資源の浪費を防ぎ、文書の種類に応じて専門家が投入するかどうかを事前に決定することで、作業効率とコストの最適化を図ることができる。
クラウドワークスによると、この技術は文書の複雑さに応じてClass 1からClass 4まで4段階に分類し、単純構造の文書は自動化前処理方式で、複雑な構造の文書は専門家解析を並行する基準を提示する。これにより、データの前処理エラーが発生する可能性を予測し、人員やスケジュール管理にも活用できるという説明である。
この技術は現在、クラウドワークスの自社開発ソリューションである「アルピナレッジコンパイラ」に適用され運営中である。このソリューションは、OCR(光学文字読み取り)、解析、チャンキング機能に基づいて、さまざまな形式の文書をAIが学習可能な形式に変換し、ハングル(HWP / HWPX)、PDF、ワード、Excelなどの多数の文書形式をサポートします。テーブル内の入れ子構造やチャート、イメージなどの視覚的要素まで認識してメタデータを生成し、LLM(超大型言語モデル)およびVLM(ビジョン言語モデル)を活用した高度化された処理機能も提供する予定だ。
近年、非定型データの資産化に対する企業需要が増加するにつれて、クラウドワークスは当該ソリューションを通じて国内外の多様な産業群の前処理需要に積極的に対応し、AIベースの業務自動化分野での競争力を強化していく方針だ。
キム・ウスンクラウドワークス代表は「今回の特許出願は文書複雑度分析基盤技術を通じてデータ前処理の精度と効率性を高めた最初の事例で、AIデータ前処理専門企業としての差別化を立証するきっかけ」とし「アルピナリッジコンパイラは現在多様な企業の問い合わせが続いており、企業向けAI市場で。
- 関連記事をもっと見る
Crowdworks,“文档复杂性分析”技术专利申请
人工智能科技公司Crowdworks 22日宣布,已申请其人工智能数据预处理解决方案“Alpy Knowledge Compiler”的核心技术“基于文档复杂度分析的文档自动化处理技术”专利。
该技术定量分析文档的结构复杂性,并确定是否可以在基于检索增强生成 (RAG) 开发 AI 代理所必需的非结构化数据预处理过程中应用自动化。根据文档类型提前决定是否需要专家参与,可以防止预处理质量下降和资源浪费,提高工作效率和优化成本。
据Crowdworks介绍,该技术根据文档的复杂程度将文档分为1类至4类四个级别,并提出了对结构简单的文档进行自动预处理、对结构复杂的文档进行专家解析的标准。这可用于预测数据预处理错误的可能性,也可用于人力资源和进度管理。
该技术目前正在Crowdworks自主研发的解决方案“RP Knowledge Compiler”中应用和运行。该解决方案基于OCR(光学字符识别)、解析和分块功能将各种文档格式转换为AI可学习的格式,并支持韩语(HWP/HWPX)、PDF、Word和Excel等多种文档格式。它将通过识别表格中的嵌套结构、图表和图像等视觉元素来生成元数据,还将使用 LLM(大型语言模型)和 VLM(视觉语言模型)提供高级处理功能。
随着近期企业对非结构化数据资产管理的需求不断增加,Crowdworks 计划通过其解决方案积极响应国内外各行业的预处理需求,并加强其在基于人工智能的工作自动化领域的竞争力。
Crowdworks首席执行官金宇胜表示:“此次专利申请是通过基于文档复杂性分析的技术提高数据预处理精度和效率的首个案例,也是证明我们作为专业AI数据预处理公司差异化优势的机会。”他补充道:“我们目前正在收到来自各个公司关于 RPI 知识编译器的询问,我们期待其在企业 AI 市场中得到更广泛的应用。”
- 查看更多相关文章
Demande de brevet pour la technologie « Analyse de la complexité des documents » de Crowdworks
La société de technologie d'IA Crowdworks a annoncé le 22 qu'elle avait déposé une demande de brevet pour la « Document Complexity Analysis-Based Document Automation Processing Technology », une technologie de base appliquée à sa solution de prétraitement de données d'IA « Alpy Knowledge Compiler ».
La technologie analyse quantitativement la complexité structurelle des documents et détermine si l'automatisation peut être appliquée pendant le processus de prétraitement des données non structurées essentiel au développement d'agents d'IA basés sur la génération augmentée de récupération (RAG). Il peut empêcher la dégradation de la qualité du prétraitement et le gaspillage des ressources, et améliorer l'efficacité du travail et l'optimisation des coûts en décidant à l'avance s'il faut impliquer des experts en fonction du type de document.
Selon Crowdworks, cette technologie classe les documents en quatre niveaux, de la classe 1 à la classe 4, en fonction de leur complexité, et propose une norme pour le prétraitement automatique des documents avec des structures simples et l'analyse experte des documents avec des structures complexes. Cela peut être utilisé pour prédire la possibilité d’erreurs de prétraitement des données et peut également être utilisé pour les ressources humaines et la gestion des calendriers.
La technologie est actuellement appliquée et exploitée dans la solution développée par Crowdworks, « RP Knowledge Compiler ». Cette solution convertit divers formats de documents en formats apprenables par l'IA basés sur des fonctions OCR (reconnaissance optique de caractères), d'analyse et de segmentation, et prend en charge plusieurs formats de documents tels que Hangul (HWP/HWPX), PDF, Word et Excel. Il générera des métadonnées en reconnaissant des éléments visuels tels que des structures imbriquées, des graphiques et des images dans des tableaux, et fournira également des fonctions de traitement avancées à l'aide de LLM (Large Language Model) et VLM (Vision Language Model).
Alors que la demande des entreprises en matière de gestion d'actifs de données non structurées a récemment augmenté, Crowdworks prévoit de répondre activement aux besoins de prétraitement de diverses industries au pays et à l'étranger grâce à ses solutions et de renforcer sa compétitivité dans le domaine de l'automatisation du travail basée sur l'IA.
Kim Woo-seung, PDG de Crowdworks, a déclaré : « Cette demande de brevet est le premier cas d'augmentation de la précision et de l'efficacité du prétraitement des données grâce à une technologie basée sur l'analyse de la complexité des documents, et c'est une opportunité de prouver notre différenciation en tant qu'entreprise spécialisée dans le prétraitement des données d'IA. » Il a ajouté : « Nous recevons actuellement des demandes de renseignements de diverses entreprises concernant le compilateur de connaissances RPI, et nous prévoyons son application élargie sur le marché de l'IA d'entreprise. »
- Voir plus d'articles connexes
You must be logged in to post a comment.